空間データベース/空間インデックス
空間インデックス(spatial index)は、カーナビで「今いる場所の近くにあるコンビニを探す」ために使われる、データベースのメカニズムのひとつ。普通のデータベースのインデックスと違うのは、扱うデータが二次元(あるいはもっと多次元)なことだ。今回は、なぜ二次元だと普通の(一次元の)インデックスじゃダメなのかを書いてみる。
普通のデータベースでの検索
普通のデータベースとして、例えば「1000人分の学生と、期末テストの合計点のデータベース」みたいなのを考えてみる。太郎君の点数が 550 点だったとき「太郎君の順位の前後 2 人のリストを作る」ときに、どうすればいいか考えてみる。いろんな方法はあるんだけど、とりあえず以下の方法でやってみる。
- 全員のデータを配列に入れる。
- 点数の低い順に並べる。
- 配列の先頭から見て行って、太郎君のデータを探す
- 太郎君のデータから、配列を前後にそれぞれ 2 人たどる
これで、太郎君の前後 2 人の学生リストを作ることができる。上の手順を 2 までやっておけば、「太郎君の順位の前後 5 人のリストを作れ」といわれても、3 の手順からやればいい。
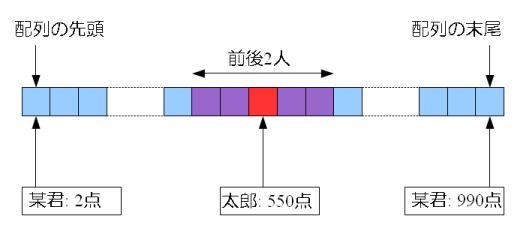
インデックスとは「データベースの一部のデータにアクセスする(読み書きするという意味)だけで、目的のデータを探せる」ようにする仕組みのことだ。単純に、アクセスするデータの数が少なければ少ないほど「高速に」探せる。上の例での操作でいえば、2 までの操作が「インデックスを作っている」部分にあたり、3 からの操作が「探す(=検索する)」部分にあたる。2 までの操作、つまりインデックスを作っておけば、「ある学生の順位の前後 X 人のリストを作れ」という操作に関しては、必ずしもデータ全てを見なくても、リストを作ることができる。
ここでやった方法だと、運が悪いと全部を見ないといけない場合もあるけど、実際のデータベースでは「ほとんどのデータにアクセスせずにデータを探す」ことができるインデックスが使われている。
空間データベースでの検索
さて、じゃあ次に「大学の中にいる 1000 人の学生の位置のデータベース」みたいなのを考えてみる。今、下の図の青い点で示してあるような感じで 1000 人がキャンバス内に散らばっているとしよう。太郎君がいる位置は赤い点で示してある。ここで「太郎君の近くにいる順に 2 人のリストを作る」ときに、どうすればいいか考えてみる。なんとなく、期末テストのデータの時と似ているので、同じ方法で出来そうな気がする。やってみる。
- 全員のデータを配列に入れる。
- ??の低い順に並べる。 ← おや?
同じ方法でやろうとすると、この「低い順に並べる」というところでつまずく。「じゃあどっか基準の点を決めて、そこに近い順に並べたらいいんじゃ?」という気がするかもしれないので、キャンバスの中心を基準にして、そこから近い順に点を並べてみる。すると、下の図みたいに順序がつく。点の横に書いてあるのが順序だ。
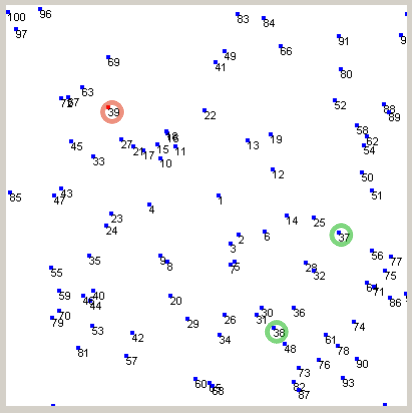
次に太郎君のデータを探すのはいいとして、この順序を使って太郎君から近い順に 2 人探そうとすると・・・見ての通り、最初につけておいた順序が役に立たない。太郎君の番号の前後の学生は、太郎君の近くにいない。理由は簡単で「距離を測った基準の点(画面中央)からの順序」が、「太郎君に近い人の順序」と全く一致していないからだ。
「じゃあ太郎君からの距離順に並べたらいいんじゃ」という意見もありそうなので、そのとおり並べ替えてみる。並べ替えたのは下の図。この図の中の順序を使えば、確かに探しやすくなった。これでいいような気がするんだけど、だめなのか?

ここで「次郎君から近い順に2人探して」と言われたらどうだろうか。次郎くんは 6 番の点だとしたら、7 や 5 の学生は次郎君のすぐ近くにはいない。このように、太郎君からの「近い順」は次郎くんからの「近い順」とは無関係なのは、さっきの場合と同じ。つまり、この操作をしようと思ったら、また「次郎くんから近い順に全部のデータを並べ替える」という操作が必要になる。言い換えれば検索するたびに全てのデータにアクセスしているわけだ。この方法はインデックスとして機能していない。
一次元のデータと二次元のデータ
なぜ位置のデータではうまくいかないのかというと、一次元のデータ(期末テストの得点)と二次元のデータ(位置のデータ)で「距離」の性質が違っていることに原因がある。
太郎君、次郎君、花子さんの3人の期末テストの点数について、太郎君と次郎君のどっちが花子さんの点数に近いか調べる方法を考えている。三人の点数がそれぞれ以下のようになっていたとする。
- 太郎君:550点
- 次郎君:400点
- 花子さん:次郎君と50点差
今、花子さんの点数はわからない。でも、この時点で、次郎君のほうが花子さんの点数に近いことが分かる。花子さんの点数として有り得るのは 350 点か 450 点のどっちかで、どっちにしても太郎君との点差は 50 以下にはならないということが、これだけの情報でわかるからだ。
もし花子さんと次郎君の点差が 100 点差だったときは、太郎君のほうが近い可能性がある。でも「次郎君は花子さんより点数が低い」という情報があれば、花子さんの点数は 500 点だとわかり、太郎君のほうが近いと分かる。
これは、点数という「一次元の」データが、次の二つの性質を満たしているためだ。
- A,B 間の点差(距離) = A, C 間の点差 + C, B 間の点差
- A の点数 ≦ B の点数, B の点数 ≦ C の点数 ならば A の点数 ≦ C の点数(全順序性)
一方、位置という「二次元の」データは、この性質を満たさない。さっきと同じように、太郎君、次郎君、花子さんの3人の位置を使って、太郎君と次郎君のどっちが花子さんの近くにいるか調べる方法を考えている。三人の位置座標がそれぞれ以下のようになっていたとする。
- 太郎君:(5,0)
- 次郎君:(0,5)
- 花子さん:次郎君から 5 の距離
わかっている情報の量としては、期末テストの場合と変わらない。しかし、これだけでは花子さんがどっちに近いのか全く分からない。図で書いてみると、その分からなさがよくわかる。
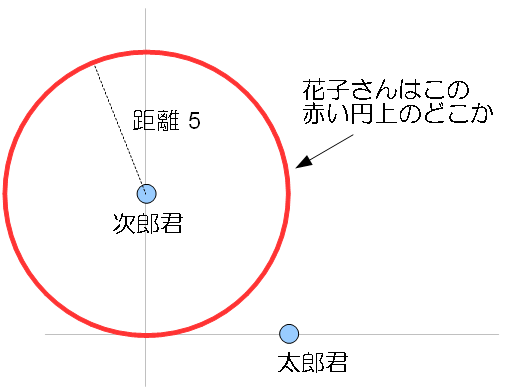
見ての通り、花子さんがいる可能性があるのは、図にかかれた円の上のどこかになる。あまりに候補の点が多い(というか無限個)で、特定しようがない。仮にここで「花子さんは次郎君より原点(0,0)に近い」という情報が得られても、花子さんのいる範囲が円弧状にちょっと狭まるものの、まだどっちに近いか分からない。
二次元のデータは、一次元のデータのような距離の足し算が成り立たない上に、データ間に順序を一意に付けることができないために、こういうことが起こってしまう。
距離
では、一次元のデータと二次元のデータの違いはなんだろうか。それは、データを探すときに使う「距離」の計算方法の違いである。一次元のデータの場合、距離は単純に二つのデータ(数値)の差で求まる。一方、二次元のデータの場合はそうはいかない。二次元のデータの場合、多くの場合「ユークリッド距離」という距離が使われる。
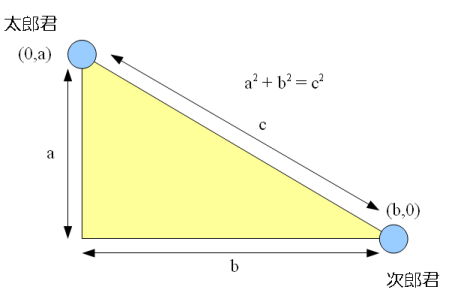
p1 = (x1, y1), p2 = (x2, y2) とする。
二点 p1, p2 間のユークリッド距離 D(p1,p2) は次の式で与えられる。
数式が出てるけど、何のことはなくていわゆるピタゴラスの定理というやつを使っている。x 軸方向と、y 軸方向の距離差をそれぞれ直角三角形の、直角を挟む二辺と見立てて、底辺の長さを求めているにすぎない。カーナビのように二次元のデータである地図を使う装置では、二つの場所の間の直線距離を求めるときには、この式を使って計算している。
逆に言えば、このユークリッド距離を使って距離を測るデータが「二次元データ」とも言える。数値が2つあるから二次元、というわけではない。
例えば「数学と国語の点数のデータ」は、データとしての数値が二つある。でもこれは二次元のデータではない。「一次元のデータがふたつ」だ。なぜなら、点数を比べるときに、数学の点数は数学の点数とだけ、国語の点数は国語の点数とだけしか比べないからだ。数学と国語の点数を混ぜて比べるようなことはしない。仮に合計で比べるとしても、それは「算数と国語の合計の点数」という一次元のデータとして比べるにすぎない。
なお、三次元以上のデータの距離にも「ユークリッド距離」を使う。その性質は二次元の場合と変わらない。一次元と二次元の距離の間には大きな差があるけど、二次元と三次元の間には距離の性質に差はない。
参考文献
ちょっと古いけど、空間インデックスについては下記論文を読むととっても勉強になる。英語だけどね。ここのブログでの記事が続くとしたら、この論文の解説みたいになってくはず。
- Authors: Volker Gaede, Oliver Gunther
- Title: Multidimensional access methods
- ACM Computing Surveys (CSUR) archive
- Volume 30 , Issue 2 (June 1998) table of contents
- Pages: 170 - 231
- Year of Publication: 1998
- ISSN:0360-0300
PDF は、論文のタイトルで Google で検索すれば出てくる。